Нейроускоритель "Каскад"
Функционально-операторное устройство. Может поставляться по требованию заказчика как отдельно выделенный продукт, так и в составе Стационарной или Мобильной машины.
Функционально-операторное устройство. Может поставляться по требованию заказчика как отдельно выделенный продукт, так и в составе Стационарной или Мобильной машины.
АО "ИЦРОН" разработал универсальный нейроускоритель (ФОУ) "КАСКАД". Предлагаемое устройство обладает рядом преимуществ по сравнению с традиционными процессорами (CPU) и графическими картами (GPU).
Высокая производительность
Каждый модуль нейроускорителя содержит многоядерную структуру и обеспечивает высокую производительность благодаря своей архитектуре, оптимизированной для параллельных вычислений
Гибкость
Нейроускорители могут использоваться для различных задач, включая обработку изображений, обработку звуков, обработку линейных сигналов в реальном времени и другие области, где может быть применен искусственный интеллект
Масштабируемость
Нейроускорители можно объединять в кластеры (интеллектуальные платформы) для обработки больших объёмов данных и сложных моделей
Оптимизация для глубокого обучения
Архитектура нейроускорителей оптимизирована для выполнения операций для глубокого обучения
В качестве стационарного, устройство может применяться как инструмент обработки крупных массивов информации, выделения тональностей, реагирования на изменение весов, обработки данных с большого количества датчиков в режиме реального времени, для развертывания и дообучения больших языковых моделей, задач, связанных с задачами в области SAT-решателей.
В качестве локального и переносного устройства, может быть применено в робототехнике, моделях машинного зрения, а так же решениях, связанных с ориентацией в пространстве.
Вычислительный модуль выполнен на базе FPGA с расчетными характеристиками, требуемыми от конкретно поставленной задачи.
Устройство в стационарном исполнении предназначено для обработки большого потока информации, с пропускной способностью от 100Гбит/сек до необходимого масштабирования. Развернутый инференс модели (AI/ML) помогает осуществлять предобработку данных, переводя входящую информацию в язык, понятный устройством. Вычислительные операции производятся непосредственно в памяти устройства, не зависимо от вычислительных процессов, происходящих в сервере. Устройство может работать в режиме офлайн, без привязки к облачному сервису, применяя исключительно инференс моделей (AI/ML), при этом необходима точная настройка устройства. Во втором случае, возможна привязка к удаленному и защищенному облачному сервису, для подкачки дополнительных данных и выгрузки необходимой информации, для управления. При тяжелых вычислениях, существует масштабирование устройств, работающих как цельная платформа.
Устройство в мобильном исполнении предназначено для обработки потока информации, входящей на блок ПЛК (программируемый логический контроллер). Информация предобрабатывается дополнительным программным обеспечением, потом к нему применяется алгоритм инференса ИНС (искусственных нейронных сетей), который получил необходимый оптимизированный вид на стационарном устройстве. Вычислительные операции производятся непосредственно в памяти устройства. После обработки полученные данные передаются в управляющее устройство. Возможна пакетная передача данных на удаленное устройство с использованием протоколов передачи коммуникационного протокола, основанного на архитектуре «ведущий — ведомый» типа Modbus.
Наше ФОУ принимает первичную информацию от коммуникационных устройств или от управляющего устройства (серверного оборудование), осуществляющего сбор первичной информации и предобработку потока массива информации. Данные подготавливаются и обрабатываются предобученными алгоритмами инференса нейросетей. При обработке информации в стационарном исполнении и режиме настоящего времени нужные алгоритмы могут дополнительно подкачиваться с помощью облачных решений.
В мобильном исполнении устройство в формате офлайн так же в режиме реального времени, используя технологию TinyML, обрабатывает входящую информацию и передает готовые данные на конечное исполнительное устройство.
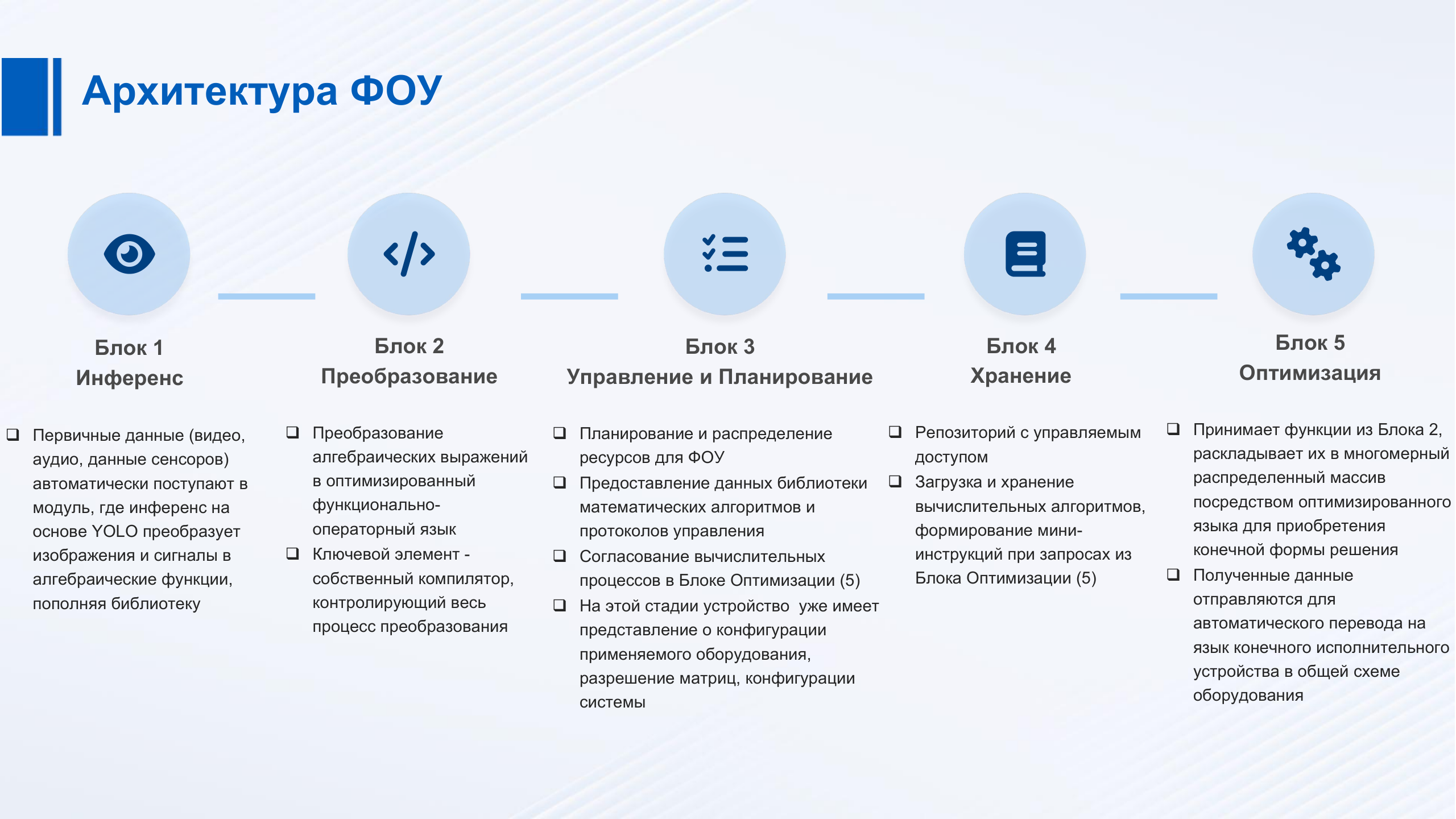
Функционально обработку поступающей информации можно представить в виде потока, который в автоматическом режиме переводится в массив на операторный язык. Затем устройство определяет его как оптимизированные алгебраические функции и распределяет их по всей площади микроядер. Управляющее программное устройство воспринимает параллельно соединенные платы FPGA в виде объединенной связки и распоряжается ими как единым цельным ресурсом.
После кратной синхронизированной обработки загруженных данных, устройство фактически мгновенно выдает оптимизированный результат в обрабатывающий блок для формирования конечного результата выполнимости задачи.
Нажмите Заказать и наш сотрудник свяжется с вами



